AWSのRDSには、リードキャパシティという機能があります。
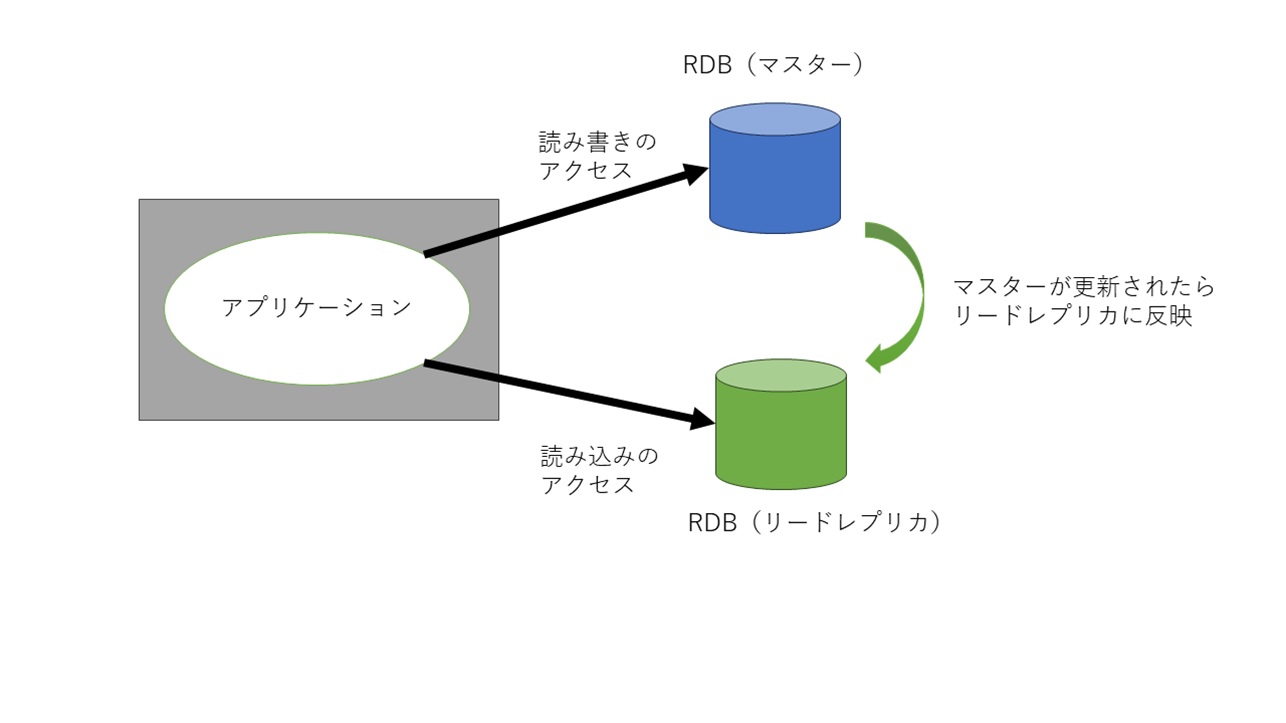
更新用データベース(マスター)から レプリカつまり、データベースのコピーを作ってしまう機能です。
更新用データベース(マスター)を更新すると 、自動的にリードレプリカ側にその更新が反映されるものです。
データベースのコピーと言われると、障害対策用にバックアップとして、取っておくというイメージが強いと思います。
特徴的なのは、その リードレプリカが、普通にデータベースを読めてしまうことです。読むことができるレプリカなので リードレプリカなのでしょう。
そうすると、更新用のデータベースと読み込み用のデータベースが用意されることになります。プログラム側で、更新時用のデータベース の接続と、 読み込み用のデータベース の接続を分けて管理してあげれば、すべての接続を1つの更新用のデータベース に接続するよりも、負荷の分散ができるようになることになります。
更新用データベース(マスター)を更新すると 、自動的にリードレプリカ側にその更新が反映されるといっても、ちょっとラグがある場合があります。更新するデータ量が多く、同期するのに時間がかかれば仕方のないことかもしれません。人間感覚てきには“すぐに”、プログラム感覚的には“少ししたら”ぐらいといった、これは経験的な感覚です。
なので、書き込みに関わる読み込みを含め、書き込み用データベースへの接続にまかせ、読み込みしか関係ない場合は、 リードレプリカに接続して、データベースアクセスを分散させたりしています。
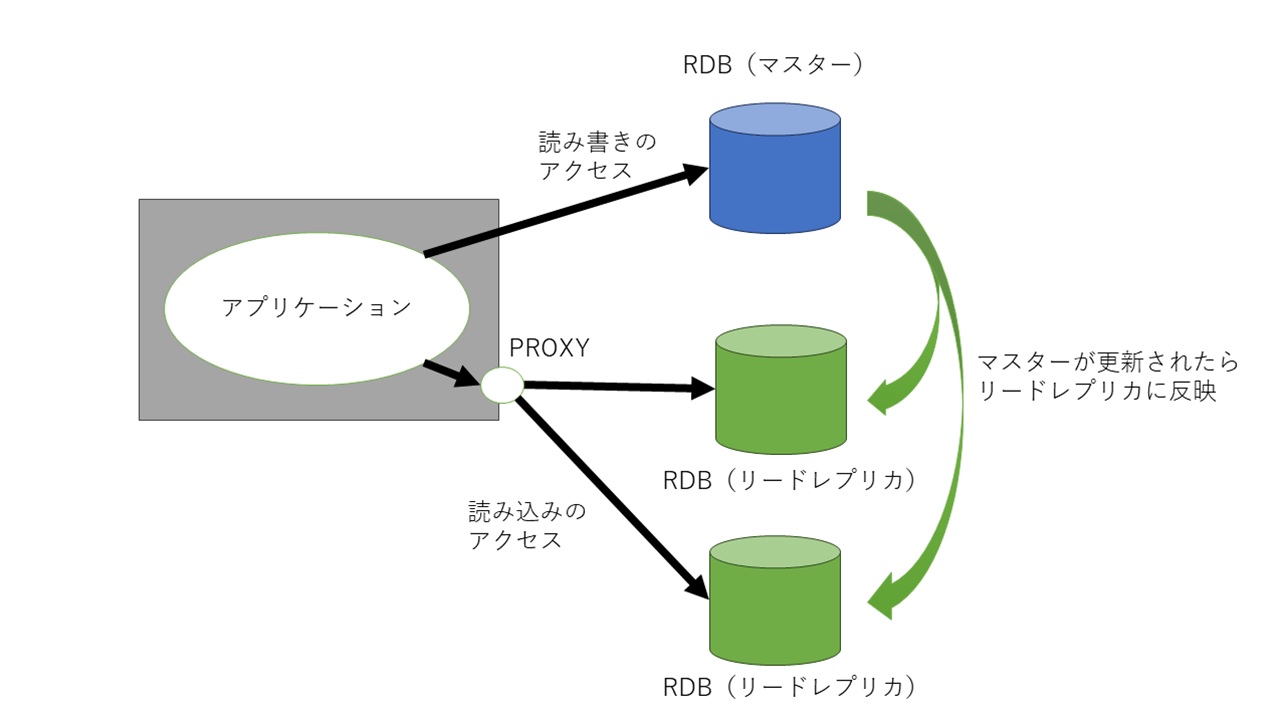
リードレプリカは複数作成することができます。マスター1つに対しいて、2つのリードレプリカを作るといったものです。マスターを更新すると、両方のリードレプリカが更新されます。RDBのエンドポイントは、それぞれに発行されます。リードレプリカが2つであれば、マスター1つとリードレプリカ2つで3つ作成されることになります。
リードレプリカそれぞれにエンドポイントがあると、どちらかのエンドポイントを指定してしまうと、接続がその1つのリードレプリカにしかアクセスが行きません。そこでPROXYを使って接続を分散させます。今回は、haproxyを使いました。